Les données sont des ressources indispensables au bon développement d’une entreprise. Elles permettent de mieux comprendre sa clientèle, analyser les stratégies de ses concurrents, décrypter un marché… Certaines informations doivent être collectées directement à partir de pages web. Pour ce faire, les sociétés s’arment d’outils de web scraping, à l’image de Data Collector de Bright Data. Retour sur cette technique utilisée dans de nombreux secteurs et sur les fonctionnalités de la solution.
Le web scraping, qu’est-ce que c’est ?
Il existe plusieurs types de data scraping : le screen scraping, qui consiste à extraire des données depuis un écran, le report mining, qui implique d’extraire des données depuis un rapport en fichier texte et, le plus populaire, le web scraping.
Inscrivez-vous à la newsletter
En vous inscrivant vous acceptez notre politique de protection des données personnelles.
Comme son nom le suggère, cette technique permet d’extraire des données depuis des pages web. Cela se fait via un programme, un logiciel automatique ou un autre site. Il existe deux méthodes :
- le web scraping manuel, qui implique de copier et de coller des informations manuellement afin de concevoir une base de données. Il s’agit d’un travail long et fastidieux, c’est pourquoi ce processus est plutôt utilisé pour collecter une petite quantité d’informations ;
- le web scraping automatique, qui consiste à utiliser un outil comme celui de Bright Data, capable d’explorer plusieurs sites internet à la fois afin de collecter et d’extraire les données souhaitées.
Qu’importe la méthode choisie, un programme de web scraping s’articule toujours en trois étapes clés :
- le fetching, c’est-à-dire le téléchargement d’une page en vue de son analyse ;
- le parsing, qui vise à extraire les données voulues dans les pages téléchargées. Des sélecteurs comme CSS ou XPath sont utilisés pour sélectionner un élément bien précis du code HTML ;
- le stockage, étape durant laquelle les informations sont structurées, exportées et stockées sur une base de données ou encore un tableau clé-valeur.
Le web scraping peut être utilisé pour plusieurs raisons, comme de la prospection. Les spécialistes du marketing scrapent souvent des sites comme LinkedIn afin d’obtenir des informations complémentaires sur certains profils. Cette technique s’avère également utile pour récupérer des renseignements commerciaux sur des concurrents, comme le listing des produits proposés.
Des templates pour accélérer le processus de web scraping
Pour permettre aux utilisateurs de scraper plus simplement des pages, Bright Data a mis au point Data Collector. L’outil est construit sur son infrastructure de proxys anti-blocages. Il est capable d’extraire instantanément des informations à partir de n’importe quel site web public. Les données peuvent être récupérées par lots ou en temps réel.
Pour aider les utilisateurs à gagner du temps lors du processus, Bright Data propose des modèles prêts à l’emploi. Il en existe pour plusieurs sites web : Amazon, Crunchbase, Wikipédia… Plusieurs sont proposés pour scraper des données sur les réseaux sociaux.
Les informations sont récupérées automatiquement. Il est possible de mettre en place une réactualisation journalière ou hebdomadaire de celles-ci.
L’outil effectue une structuration transparente des données. Pour ce faire, des algorithmes d’intelligence artificielle sont utilisés. Ils nettoient, traitent et synthétisent les informations non structurées des sites avant leur livraison. Cela permet d’avoir des jeux de données prêts à être analysés.
Problème : les structures de pages ne cessent d’évoluer sur les sites web. Cela complexifie grandement l’extraction de données. Toutefois, l’outil de Bright Data s’adapte rapidement aux changements structurels. De cette manière, les données sont toujours disponibles et utilisables.
Côté intégration, Bright Data dispose d’une API. Celle-ci peut être connectée à toutes les principales plateformes de stockage. Vous pouvez alors profiter d’un processus de collecte de données simplifié et fluide.
Il est important de souligner que l’outil est entièrement conforme aux réglementations sur la protection des données, dont le RGPD.
Un fonctionnement en quatre étapes
L’utilisation de Data Collector ne nécessite pas d’être un expert en codage ou en web scraping. Pour s’en servir, il suffit de suivre quelques étapes.
La première consiste à choisir un modèle parmi ceux proposés par Bright Data. Il doit être choisi en fonction du site sur lequel vous souhaitez scrapper des données : leboncoin, eBay, TikTok… Une bibliothèque de templates est disponible.
Dans le cas où vous ne trouveriez pas celui qu’il vous faut, il est possible de créer le vôtre. L’outil propose plusieurs fonctionnalités pour concevoir rapidement votre web scraper, comme une analyse HTML ou encore des outils prédéfinis pour les API GraphQL.
Une fois que votre modèle est prêt, vient une étape indispensable pour s’assurer de recevoir des informations structurées et complètes : la validation des données. Il faut définir la manière dont vous souhaitez les recevoir : par lots, ou en temps réel. Cela dépend entièrement de vos besoins.
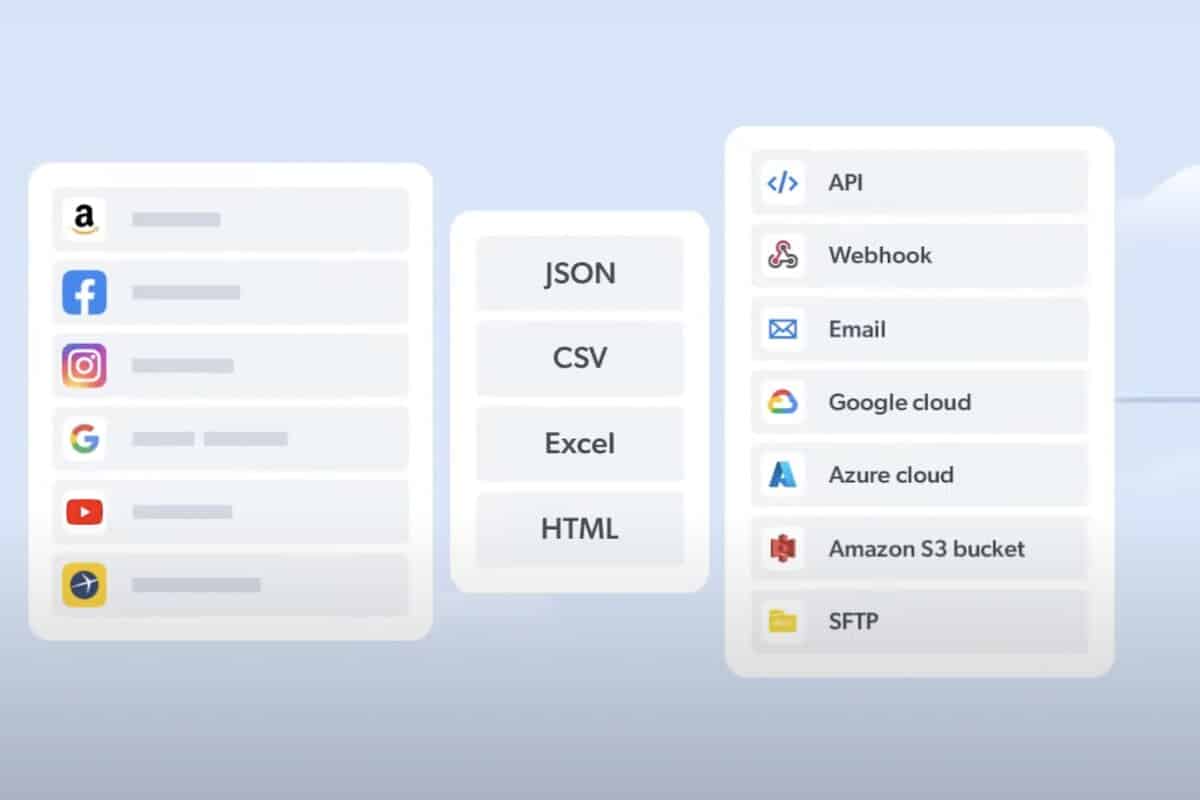
Illustration : Bright Data.
Vous devez ensuite choisir le format dans lequel vous préférez récupérer les informations collectées. Bright Data en propose plusieurs : JSON, CSV, Excel, XLSX ou encore HTML.
Enfin, vous devez sélectionner un mode de récupération. Vous pouvez vous faire livrer vos données sur les plateformes de stockage les plus courantes : API, Amazon S3, Webhook, Microsoft Azure, Google Cloud PubSub et SFTP. Les recevoir par e-mail est également une possibilité.
De nombreux cas d’utilisation
Data Collector peut servir dans plusieurs cas de figure, à commencer par l’e-commerce. L’outil peut être utilisé pour suivre l’évolution des demandes de consommateurs, identifier les prochaines grandes tendances et être alerté lors de l’arrivée de nouvelles marques sur le marché. Cela permet donc d’anticiper les grandes dynamiques du secteur et de faire une veille concurrentielle grâce à la data.
Les marketeurs et les communicants y trouveront également leur compte. Il est possible d’extraire des données issues de publications sur les réseaux sociaux, comme les mentions « J’aime », les médias ou encore les hashtags. Chaque commentaire peut être analysé pour mieux comprendre l’avis des consommateurs. In fine, cela contribue à créer des campagnes plus efficaces.
Un web scraper peut aussi être utile aux entreprises œuvrant dans le B2B. Les données collectées permettront d’identifier des prospects à contacter et d’avoir des informations pertinentes à leurs sujets, comme un e-mail ou un numéro de téléphone. Les services ressources humaines peuvent aussi se servir d’un outil de ce type pour analyser les mouvements du personnel dans une entreprise ou encore les modèles d’embauche. Vous l’aurez compris, tous les départements d’une entreprise peuvent en profiter.
De leur côté, les professionnels du tourisme peuvent exploiter un web scraper pour trouver les nouvelles offres et promotions lancées par vos concurrents et comparer leurs tarifs. On retrouve des avantages similaires pour les agents immobiliers, qui ont la possibilité d’examiner les prix des biens ou encore de localiser les maisons ou les appartements dont les loyers sont les plus élevés.
Data Collector de Bright Data dispose donc de multiples fonctionnalités pour extraire des informations de façon automatisée, les analyser et les structurer. Côté tarif, une offre vous permettant de payer au fur et à mesure des requêtes est proposée. Des formules en fonction du nombre de pages analysées sont disponibles dès 500 euros par mois.