
Si le terme intelligence artificielle est né en 1950 dans un article publié par Alan Turing, son application n’aura jamais été aussi performante que depuis ces dernières années. Néanmoins, l’IA comme domaine scientifique existe depuis 1956 suite à la conférence tenue au Darmouth College, ce qui sonne le début de l’histoire de l’intelligence artificielle. Aujourd’hui, elle vient de pair avec d’autres termes comme algorithme, machine learning, réseau de neurones artificiels, deep learning … Voyons ensemble ce qui hiérarchise tout cela.
Depuis 2012, les composants informatiques sont de plus en plus puissants et de moins en moins chers. Cela permet à des projets de recherche de voir le jour plus facilement. D’autre part, l’engouement pour l’intelligence artificielle a lancé de vastes plans d’optimisations de la collecte des données qu’il s’agisse de dossiers médicaux, d’images, de vidéos, ou des données de cartographies. C’est d’autant plus vrai lorsqu’on constate le faible coût que représente le stockage des données aujourd’hui. Grâce à tout cela, l’IA s’est perfectionnée et elle a trouvée de nouveaux terrains de jeu dans la médecine, dans le traitement des images, dans la programmation informatique, et même dans l’agriculture. C’est alors qu’émergent des termes comme machine learning, réseaux de neurones artificiels, GAN, ou encore deep learning, selon la complexité du travail appliqué à ces programmes.
Inscrivez-vous à la newsletter
En vous inscrivant vous acceptez notre politique de protection des données personnelles.
L’intelligence artificielle faible
Par définition, l’IA faible est un programme qui n’est pas doté de sens et se concentre uniquement sur la tâche pour laquelle il a été programmé. On la met en opposition à l’IA forte, qui, elle, est dotée de conscience et donc d’une sensibilité particulière. Cependant, l’IA forte reste encore du domaine de la science-fiction. Toutes les intelligences artificielles que nous croisons dans la vraie vie sont faibles.
Dans leur état le plus basique, elles ne sont qu’un algorithme qui n’évolue pas, et qui ne se base pas sur une quantité de données. Ceci en opposition au machine learning ou au deep learning. Ensuite, l’exemple le plus sommaire, d’une IA, c’est le robot contre lequel vous jouez aux échecs, à Warcraft, ou qui anime vos parties de Theme Hospital.
Dès lors que l’exploitation de la donnée entre en jeu, on commence à apprendre aux machines. Ainsi elles évoluent, se perfectionnent continuellement, et c’est dans les années 90 que le machine learning entre en jeu.
L’apprentissage automatique sacré par Deep Blue
Dès lors qu’entre en jeu un concept d’apprentissage, bon nombre de scientifiques rêvent de passer le test de Turing, évoqué en 1950 dans l’ordinateur et l’intelligence. Ce test consiste à engager une conversation masquée entre un humain, une machine, et un autre humain. Si le premier humain n’est pas en mesure de désigner l’interlocuteur qui est une machine, alors cette dernière passe le test de Turing.
La toute première fois qu’on parle de machine learning, c’est en 1959, lorsque Arthur Samuel a présenté pour IBM un programme jouant au jeu de dames. Sa particularité ? Il l’améliorait à chaque partie. L’informaticien a créé un système qui permettait au programme de se souvenir de chaque position qu’il avait déjà vu, avec les opportunités qu’elles offraient. Il l’a également fait jouer contre lui-même comme autre moyen d’apprentissage. Grâce à ces données, Arthur Samuel a fait évoluer son programme et il aurait ainsi été en mesure de battre le 4ème meilleur joueur de dames des États-Unis. Il s’agit également du premier programme informatique à jouer à un jeu de plateau à un niveau avancé.
Le véritable sacre de l’apprentissage automatique survient lorsqu’en 1997 Deep Blue bat Garry Kasparov aux échecs, invaincu jusqu’alors. Le superordinateur créé par IBM inspirera la naissance de Watson, mais aussi de nombreux projets d’apprentissage des intelligences artificielles. Le développement rapide de l’information, du traitement des données, et du cloud nous emmènera jusqu’à AlphaGo développé par DeepMind, rachetée par Google en 2014.
Depuis longtemps, nous, internautes, avons entraînés des systèmes de machine learning. En aidant à Google à identifier un chat, un panneau STOP, ou un feu de signalisation lors d’un CAPTCHA la plupart du temps. Au départ, l’IA fait difficilement la différence entre l’image d’un chat et celle d’un buisson. À force de lui dire « sur cette image il y a un chat, mais pas sur celles-ci » le programme comprend ce qu’est un chat. Seulement, pour progresser, il faut développer le bon algorithme d’apprentissage, et il faut du temps.
Aujourd’hui, le machine learning continue d’être utilisé, mais plus dans une approche où il excède : identifier un schéma à partir de données structurées. C’est ce qui différencie de le machine learning du deep learning. Dans le premier, on exploite des informations qui sont triées, classées, et renseignées. Par exemple, si je suis un e-commerçant, comment mon algorithme va savoir si tel utilisateur aurait plutôt tendance à acheter un vélo rouge qu’un vélo bleu ? Pour y arriver, on entraine l’algorithme avec une vaste quantité d’informations concrètes : la météo le jour de l’achat d’un vélo rouge, l’âge des acheteurs de vélos bleus, …
Le machine learning a posé les bases permettant de faire émerger des algorithmes d’intelligence artificielle plus complexes, creusant plus en profondeur pour arriver à leur résultat. C’est le cas des réseaux de neurones artificiels.
Plus il y a de couches, plus c’est deep
La distinction entre le machine learning et le deep learning, c’est que le premier utilise des données structurées, l’autre part dans une quête longue, à l’aveugle, avec de nombreuses étapes pour arriver à son résultat final. La structure des algorithmes de deep learning demande donc une construction bien plus complexe. C’est ce qui fait que cette approche s’épanouie dans le traitement de données graphiques par exemple. Cette même structure mime la façon dont une cerveau résonne, ce qui a fini par lui donner un nom : réseau de neurones.
Dès lors que l’on a compris l’intérêt de créer des structures complexes, avec plus de couches, et plus de données, bon nombre de projets ont vu le jour. Ils ont bien souvent été financés au sein des GAFAM, mais également dans des écoles, ou dans d’autres structures privées. Leurs applications sont nombreuses, mais les plus connus sont dédiés à l’imagerie médicale, le traitement du langage, la reconnaissance vocale, etc.
La première fois que l’on parle de deep learning, c’est grâce à la professeure Rina Dechter en 1986. Ensuite, cette approche est mise en pratique par Yann LeCun en 1989. L’actuel boss de l’IA chez Facebook avait à l’époque utilisé un réseau de neurones artificiel profond afin de reconnaître les codes postaux écrits à la main sur des lettres. Un programme simple aujourd’hui, mais qui avait nécessité trois jours d’apprentissage à l’époque.
Des recherches et des études sur la structure des réseaux de neurones continueront d’animer la communauté scientifique jusqu’en 2009, année où cette pratique prend son envol. On considère cette année comme le big bang du deep learning. À ce moment-là, Nvidia met ses processeurs graphiques (GPU) à contribution. Pour Andrew Ng, cofondateur de Google Brain, l’exploitation des GPU pourrait créer des systèmes d’apprentissage profond jusqu’à 100 fois plus rapides. L’entraînement des algorithmes passerait de plusieurs semaines à seulement quelques jours.
C’est ainsi que Andrew Ng crée une architecture avec bien plus de couches et de neurones qu’auparavant. Il l’entraîne ensuite avec des contenus provenant de 10 millions de vidéos YouTube afin que son programme puisse identifier et extraire les images avec des chats. Nous sommes en 2012.
C’est à cette date que l’IA explose véritablement. La vaste disponibilité des GPU permet de créer des traitements parallèles pour les programmes et ainsi les rendre plus rapides, moins chers, et même plus puissants. Ajoutons à cela, depuis 2015, la quantité astronomique de données que l’on peut utiliser et stocker, et les intelligences artificielles ont tout pour s’épanouir.
Aujourd’hui, des IA sont capables de faire des tâches précises bien mieux que l’Homme. Conduire, identifier une tumeur, joueur à un jeu vidéo, recommander un film, etc. Le deep learning a permis aux chercheurs de mettre en place bien des éléments pratiques du machine learning, et ce, pour un meilleur futur.
Un schéma pour tout comprendre sur l’intelligence artificielle
Toutes (ou presque) les théories d’apprentissage, les structures de réseaux de neurones artificiels, les applications de certains traitements ont vu le jour dès les premiers instants de l’intelligence artificielle. Cependant, l’informatique aura été la clé de son épanouissement et de sa mise en pratique. De l’intelligence artificielle basique au deep learning, il aura fallu attendre des décennies.
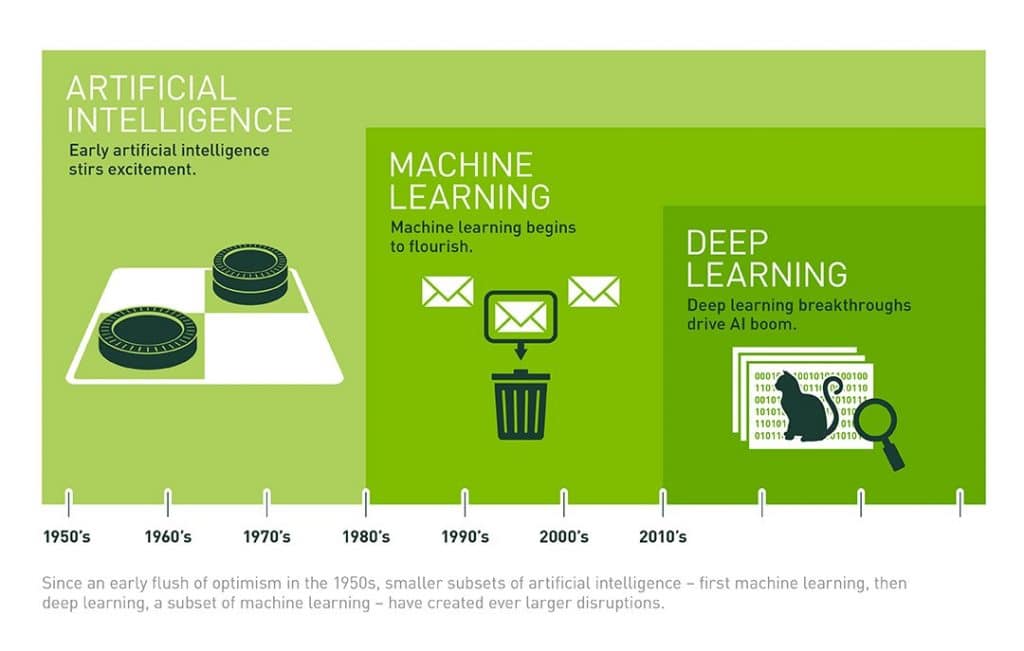
Crédit : Nvidia
Chaque approche évolue de son côté, et permet de renforcer l’autre dans le cas où l’on va plus profond dans l’apprentissage. Les structures, les fonctionnements, les concepts sont constamment remis en question. C’est le cas d’une technique que Yann LeCun a qualifié d’idée « la plus intéressante des 10 dernières années dans le domaine du Machine Learning. » : les GANs.
Les GANs rendent les IA créatives
Les GANs, ou Generative Adversarial Networks sont utilisés dans le cadre d’un entrainement intensif, mais extrêmement efficace. Deux réseaux de neurones s’opposent. Le premier (générateur) doit créer une image, mettons, un arbre. Il doit ensuite soumettre cette image parmi d’autres vraies images d’arbres. Le second (discriminateur) doit dire quelle image n’est pas celle d’un arbre, et la renvoie. Ainsi, le générateur peut confronter son image avec celles qui ont été validées, pour ensuite en recréer une meilleure, la soumettre, et ainsi de suite. La dernière étape est lorsque le discriminateur n’est plus en mesure d’éliminer une image.
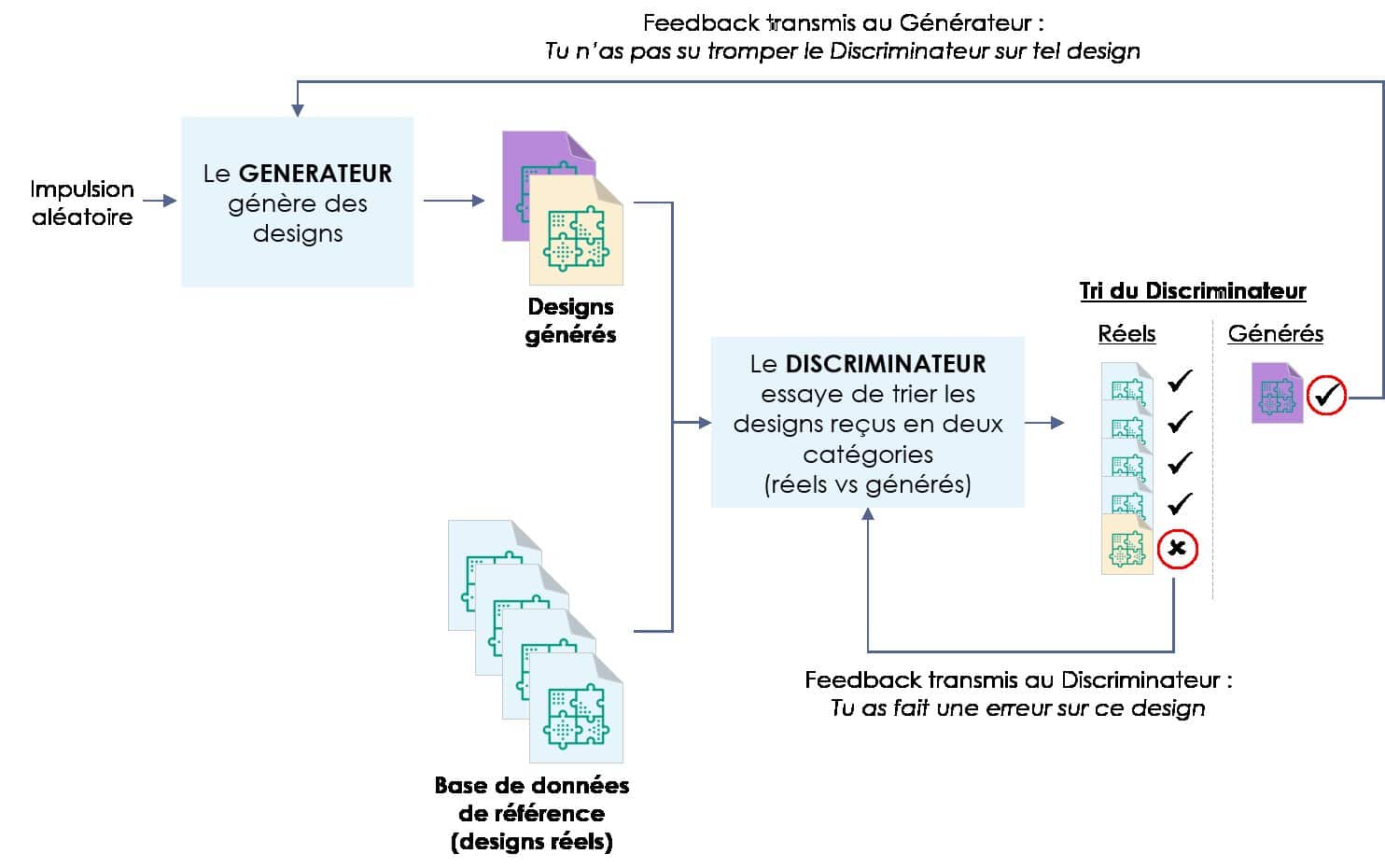
Schéma de fonctionnement d’un GAN. Crédit : Wintics
Les résultats des GANs sont bluffants. Nvidia a travaillé sur plusieurs cas de figure avec ces réseaux dont la plus impressionnante est la génération de visages que vous pouvez voir ci-dessous. S’ils semblent tous être vrais, ils n’existent pas. Ils ont été réalisés par un programme.

Crédit : Nvidia
Une application dans le design industriel fait partie des éléments sur lesquels les GANs vont être mis à contribution.
Des simples robots dans les jeux vidéo, l’intelligence artificielle occupe une place quotidienne dans nos vies aujourd’hui. Nous l’utilisons sans nous en rendre compte sur Google, Spotify, Netflix … Si Hollywood lui prête un destin de domination de l’Homme, elle n’est toujours pas programmée pour ça, et difficile de penser que ce sera le cas. Très performante sur des tâches extrêmement complexes et précises, l’IA n’est toujours pas en mesure d’avoir une intelligence générale, c’est à dire d’apprendre à être intelligente comme nous, d’apprendre le monde comme un bébé ou un enfant peut le faire.