
Les trois lauréats 2018 du prix Turing se sont penchés sur les défis de l’apprentissage profond, ou deep learning. Dans un article paru en juillet 2021 dans la revue de l’ACM, Association for Computing Machinery, Yoshua Bengio, Geoffrey Hinton et Yann LeCun estiment que le deep learning dépassera certains obstacles de son développement sans nécessiter une intelligence artificielle (IA) symbolique.
Considérés comme les pionniers du deep learning par VentureBeat, les chercheurs comparent l’apprentissage profond au fonctionnement neuronal des animaux, y compris celui de l’être humain. Bien qu’ils relèvent des différences majeures, ils affirment que les objectifs actuels sont de tendre vers une réplique de ces cerveaux vivants. Cela sous-entend que les modèles de deep learning vont vers moins d’intervention humaine.
Inscrivez-vous à la newsletter
En vous inscrivant vous acceptez notre politique de protection des données personnelles.
Le deep learning est comme le petit frère du machine learning, appelé en français apprentissage automatique. Et le machine learning, celui de l’IA symbolique. Ces trois notions permettent de faire des programmes d’IA, un terme désignant plusieurs concepts.
Avant d’entrer dans les détails, retour sur les termes principaux
L’IA symbolique désigne des techniques s’appuyant sur la manipulation de symboles pour stimuler des comportements humains dans un programme informatique. Son inconvénient réside dans l’incapacité de traiter des situations inconnues. L’IA symbolique nécessite des règles définies par avance et de l’intervention humaine.
Le machine learning s’appuie sur un algorithme qui adapte un système en fonction des données et des retours faits par des humains. Son fonctionnement nécessite des données structurées et catégorisées. Le machine learning nécessite donc beaucoup d’intervention humaine. À partir de celles-ci, le programme classe des données similaires. À titre d’exemple, les captcha s’appuient sur du machine learning. Quand un moteur de recherche demande d’identifier les feux rouges sur une photo, derrière une IA s’entraîne.
Contrairement au machine learning, le deep learning ne requiert pas de données structurées. Il fonctionne grâce à des réseaux neuronaux artificiels qui combinent plusieurs algorithmes. Cette conception informatique s’inspire directement de la structure des neurones d’un cerveau. Un réseau neuronal artificiel se compose d’au moins deux couches de neurones. Une pour l’entrée, l’autre pour la sortie. Plus il y a de couches, plus le programme résout des problèmes complexes. Une autre différence du deep learning est qu’il nécessite de plus grandes quantités de données pour fonctionner, au moins 100 millions selon Ionos, une entreprise d’hébergement web.
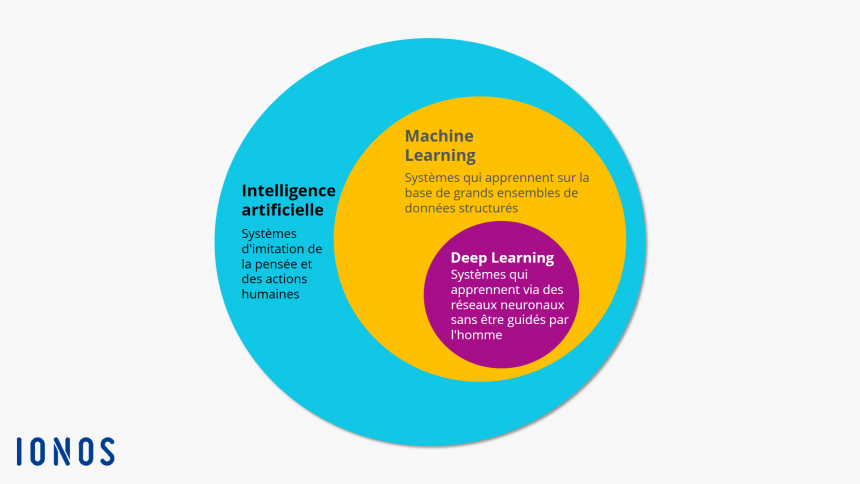
Schéma de fonctionnement de l’intelligence artificielle. Image : IONOS
Deep learning et données
Si les cerveaux des êtres vivants sont évoqués, la route est encore longue pour que les réseaux neuronaux artificiels puissent être considérés comme tels. Aujourd’hui, ces derniers n’ont ni l’efficacité, ni la flexibilité, ni la polyvalence des véritables cerveaux. « L’apprentissage supervisé [champ du machine learning], bien qu’il soit efficace dans une grande variété de tâches, nécessite généralement une grande quantité de données étiquetées par l’homme. De même, lorsque l’apprentissage par renforcement [idem] est basé uniquement sur des récompenses, il nécessite un très grand nombre d’interactions », indiquent les trois lauréats du prix Turing.
À la fois dans le cas de l’apprentissage supervisé et dans celui de l’apprentissage par renforcement, un travail humain considérable reste donc nécessaire. En effet, un jeu de données qualitatif n’est pas toujours aisé à trouver, particulièrement pour les domaines n’ayant pas de bases de données en open data, ou autre. Dès lors, il faut un travail humain fastidieux d’annotations pour compléter ou créer les données. Communément, la qualité d’une base de données est définie par les 3V : volume, vélocité et variété.
« Les performances des meilleurs systèmes d’IA actuels ont tendance à se dégrader lorsqu’ils passent du laboratoire au terrain », notent les trois informaticiens. Une autre barrière au développement de l’IA est l’hypothèse que les données du monde réel ont la même répartition que celles utilisées pour entraîner le programme et sont indépendantes. En statistique, cette problématique correspond à des variables indépendantes et identiquement distribuées (iid). Cette approche reste trop éloignée d’une application dans la vie réelle.
« Les humains peuvent généraliser d’une manière différente et plus puissante que la généralisation iid ordinaire : nous pouvons interpréter correctement de nouvelles combinaisons de concepts existants, même si ces combinaisons sont extrêmement improbables », explique l’article.
Réduire l’écart entre intelligence humaine et artificielle
Ces programmes sont donc « souvent fragiles en dehors du domaine étroit dans lequel ils ont été entraînés », écrivent les chercheurs. Quelques pixels modifiés ou une légère altération de leur environnement peuvent grandement les perturber. Les réponses aujourd’hui apportées consistent à entraîner les réseaux neuronaux artificiels avec davantage de données. L’idée est qu’avec une plus large couverture, les risques d’erreurs dans la vraie vie sont réduits.
« Les humains et les animaux semblent être capables d’apprendre des quantités massives de connaissances sur le monde, en grande partie par l’observation, d’une manière indépendante de la tâche. Ces connaissances soutiennent le sens commun et permettent d’apprendre des tâches complexes, comme la conduite, avec seulement quelques heures de pratique », mentionnent Yoshua Bengio, Geoffrey Hinton et Yann LeCun.
Une des solutions couramment avancée pour répondre à cette problématique est l’IA hybride. Soit une IA composée d’un réseau neuronal artificiel et d’une IA symbolique. Dans une vidéo accompagnant leur article, les chercheurs contredisent cette approche. Pour eux, le développement de l’IA réside dans l’amélioration des réseaux neuronaux artificiels.
Les avancées prometteuses de deep learning
Les trois lauréats du prix Turing mettent la lumière sur le réseau neuronal artificiel Transformer. Son atout réside dans sa capacité d’apprentissage qui ne nécessite pas de données étiquetées. Ce système est utilisé pour l’IA GPT-3 d’OpenAI qui est capable de rédiger un mémoire de fin d’études en moins de 20 minutes ainsi que pour l’IA de Google Meena. Sans apprentissage supervisé, le réseau Transfromer peut développer des représentations qui ensuite peuvent notamment remplir des phrases incomplètes et générer un texte.
Les chercheurs mettent également en avant l’apprentissage contrastif. Au lieu de prédire l’emplacement exact d’un pixel, ce système tente de trouver des représentations vectorielles. En application, dans l’exemple de l’image ci-dessous, un système doté d’un apprentissage contrastif reconnaît les zones vertes comme des fenêtres sans les définir précisément. Ce mécanisme se rapproche davantage du fonctionnement du cerveau humain.

Avec l’apprentissage contrastif l’IA devine les fenêtres derrière les carrés verts. Credit: Flickr Creative Commons/Michael/Alzheimer’s Followers
Le deep learning système 2 est également salué par Yoshua Bengio, Geoffrey Hinton et Yann LeCun. Il s’inspire des fonctions du cerveau nécessitant une réflexion consciente, permettant de raisonner ou encore de résoudre des problèmes comportant plusieurs étapes. Dans ce domaine, la recherche en est encore à ses débuts. Les prémices de celle-ci indiquent que le deep learning système 2 pourrait résoudre de nombreux problèmes dans les systèmes neuronaux artificiels. Enfin, les chercheurs soulignent les avancées dans les réseaux neuronaux à capsule (CapsNet). Ce système permet une meilleure modélisation grâce à une forme « d’intuition ». Chez les animaux, cette capacité permet d’aborder les environnements tridimensionnels.
« Il y a encore beaucoup de chemin à parcourir pour comprendre comment rendre les réseaux neuronaux vraiment efficaces. Et nous nous attendons à ce qu’il y ait des idées radicalement nouvelles », présage Geoffrey Hinton. Aussi, les moyens demeurent un frein. En effet, un programme de deep learning nécessite de nombreuses ressources informatiques, et donc financières, que seuls quelques laboratoires et entreprises peuvent s’offrir.