Après PDFify, le logiciel de Mac qui transforme le texte de vos images en PDF, c’est à Dropbox de lancer sa fonctionnalité de reconnaissance de texte. Selon eux, plus de 20 milliards d’images et de documents en format PDF sont stockés sur Dropbox. 10 à 20% d’entre eux sont des photos de documents prises par les utilisateurs.
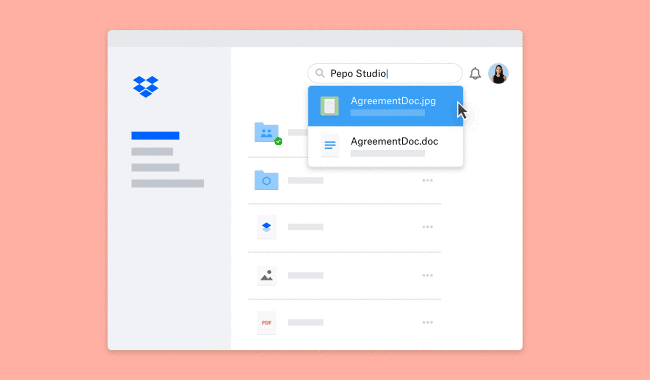
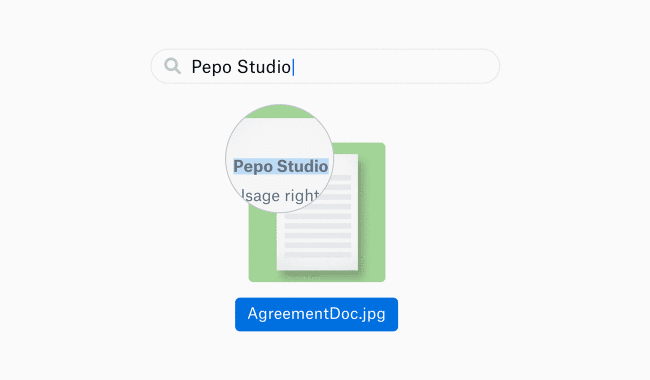
Avec cette nouvelle option, Dropbox répond donc à un besoin qui fait partie de sa démarche DBXi : celui de pouvoir rechercher du texte dans les images. Cette recherche intelligente est possible grâce au machine learning. Tout comme une recherche traditionnelle, l’utilisateur doit simplement taper le mot ou la phrase clé qu’il souhaite retrouver. Ensuite, Dropbox listera tous les documents où cette requête figure.
Inscrivez-vous à la newsletter
En vous inscrivant vous acceptez notre politique de protection des données personnelles.
© Dropbox
Dropbox s’est exprimé sur la technologie et a expliqué que cette démarche était complexe et intense pour son équipe de machine learning. Les documents PDF ont représenté un réel défi, car ils contiennent bien plus de texte qu’une simple image. La technologie derrière la nouvelle reconnaissance de texte n’analyse donc que les 10 premières pages d’un document PDF. Sinon, le process serait trop lourd.
Tous les documents sous format JPEG, GIF, PNG, TIFF et PDF, même ceux enregistré sur le service de stockage avant le déploiement de la fonctionnalité seront automatiquement analysés et scannés. Pour l’instant, la reconnaissance de texte fonctionne en langue anglaise uniquement sur certains types de comptes : les comptes Dropbox Professional verront l’option apparaître dans les prochains moins, les personnes ayant un compte Business Advanced ou un compte entreprise peuvent désormais visiter la console d’administration pour en savoir plus.