
La firme de Mountain View a annoncé le lancement d’un nouveau service de synthétiseur vocal appelé Cloud Text-to-Speech. Google a renforcé cet outil grâce à l’intelligence artificielle de sa filiale DeepMind.
Cloud Text-to-Speech va permettre aux développeurs de synthétiser des voix avec une intonation proche de la nôtre. 30 voix différentes sont disponibles et réparties sur 12 langues comprenant des particularités comme l’anglais australien, ou le français canadien. Pour certaines langues, Google propose soit une synthétisation basique, soit une autre développée grâce à DeepMind, appelée WaveNet.
Inscrivez-vous à la newsletter
En vous inscrivant vous acceptez notre politique de protection des données personnelles.
WaveNet crée une voix plus naturelle, et produit logiquement un son que les utilisateurs préféreront entendre face à quelque chose de plus ‘robotisé’. La première version de cette technologie a vu le jour en 2016 et se concrétise dans un réseau de neurones artificiels entraîné avec une grande quantité d’échantillons de voix. Cela lui permet de créer entièrement une synthétisation vocale. En évoluant, la filiale de Google a amélioré le temps de production des fichiers en le rendant 1000 fois plus rapide afin de produire 20 secondes d’audio en 1 seconde.
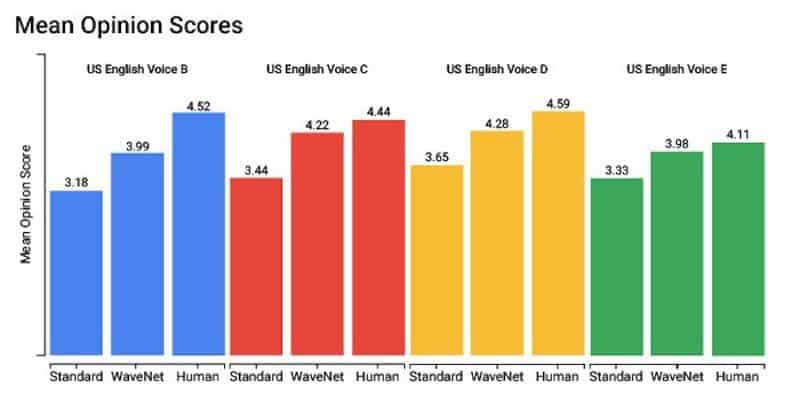
Comparaison de la qualité des voix créées avec Cloud Text-to-Speech et la technologie WaveNet
WaveNet de DeepMind a été intégré pour la toute première fois au mois d’octobre dans Google Assistant, pour les anglophones et les japonais. En évoluant, on devrait rapidement pouvoir l’utiliser pour synthétiser des voix françaises dans une meilleure qualité que celles proposées par Cloud Text-to-Speech, ou Polly d’Amazon.