
« Les 10 dernières années ont été sur la construction d’un monde qui est first-mobile. Au cours des 10 prochaines années, nous allons passer à un monde qui est IA-première. » (Sundar Pichai, PDG de Google, octobre 2016)
De Amazon et Facebook à Google et Microsoft, les dirigeants des entreprises technologiques les plus influents du monde mettent en avant leur enthousiasme pour l’intelligence artificielle (IA). Mais quelle est cette technologie ? Pourquoi est-ce si important ? Et pourquoi maintenant ? Bien qu’il y ait un intérêt croissant pour l’IA, le domaine est entendu principalement par des spécialistes. L’objectif de cet article est de rendre ce domaine accessible à un plus large public.
Tentons d’expliquer le sens de l’IA et des termes clés, y compris « machine learning ». Tout d’abord, nous illustrerons comment l’une des zones les plus productives de l’IA, appelé « deep learning » fonctionne. Ensuite, nous inspecterons les problèmes que résolvent les intelligences artificielles et pourquoi elles sont importantes. Enfin, nous explorerons au travers de l’article pourquoi l’intelligence artificielle, qui a été inventée dans les années 1950, en est venue à son âge d’or aujourd’hui.
Inscrivez-vous à la newsletter
En vous inscrivant vous acceptez notre politique de protection des données personnelles.
Comme pour les investisseurs, nous recherchons des tendances émergentes qui créeront de la valeur pour les consommateurs et les entreprises. Nous croyons que l’IA est une évolution de l’informatique, sinon plus importante que les changements liés à l’informatique mobile ou du cloud. « Il est difficile d’exagérer, la taille de l’impact que l’IA va avoir sur la société au cours des 20 prochaines années, » nous dit le PDG d’Amazon Jeff Bezos. Si vous êtes un consommateur ou un cadre, un entrepreneur ou un investisseur, cette nouvelle tendance sera importante pour vous tous.
Qu’est-ce que l’intelligence artificielle ?
Intelligence artificielle : la science des programmes intelligents.
Inventé en 1956 par John McCarthy Professeur adjoint de l’Université de Dartmouth, IA est un terme général qui désigne matériel ou logiciel qui présente un comportement qui semble intelligent. Dans les mots du professeur McCarthy, il est : « la science et de l’ingénierie de fabrication des machines intelligentes, notamment des programmes informatiques intelligents. »
Cette technologie existe depuis des décennies, grâce à des programmes fondés sur des règles qui offrent des cas rudimentaires d’intelligence dans des contextes spécifiques. Toutefois, les progrès ont été limités parce qu’il est extrêmement complexe de programmer à la main les algorithmes.
Les activités sophistiquées, y compris établir des diagnostics médicaux, de prédire quand les machines tomberont en panne ou évaluer la valeur de marché de certains actifs, impliquent des milliers de jeux de données et des relations non linéaires entre les variables. Dans ces cas, il est difficile d’utiliser les données que nous avons au mieux à optimiser nos prévisions. Dans d’autres cas, y compris la reconnaissance des objets dans les images et la traduction de langues, nous ne pouvons même pas élaborer des règles pour décrire les caractéristiques que nous recherchons. Comment pouvons-nous écrire un ensemble de règles qui décrivent l’apparence d’un chien ?
Et si nous pouvions transférer la difficulté de faire des prévisions complexes – l’optimisation des données et la spécification de fonction - du programmeur au programme ? Telle est la promesse de l’intelligence artificielle moderne.
Machine Learning : optimisation de déchargement.
Machine Learining (ML) est un sous-ensemble de l’IA. Tout ML est AI, mais toute IA n’est pas ML (Figure 1). L’intérêt pour aujourd’hui de l’IA reflète l’enthousiasme pour le ML, où les progrès sont rapides et importants.

En outre, le machine learning permet de nous attaquer à des problèmes qui sont trop complexes à résoudre pour les humains en transférant une partie de la charge à l’algorithme. Comme l’a écrit le pionnier Arthur Samuel en 1959, le machine learning est le « champ d’étude qui donne aux ordinateurs la capacité d’apprendre sans être explicitement programmés à apprendre ».
Par la suite, l’objectif de la plupart des ML est de développer un moteur de prédiction pour un cas d’utilisation particulier. Un algorithme recevra des informations sur un domaine (par exemple, tous les films qu’une personne a regardé dans le passé) et analysera ces données pour en faire une prédiction utile (la probabilité de la personne aimant un nouveau film). En donnant aux ordinateurs « la capacité d’apprendre », nous laissons la tâche complexe d’optimisation (le contrôle et l’analyse des variables dans les données disponibles pour en faire des prédictions précises sur l’avenir) à l’algorithme. Parfois, nous pouvons aller plus loin, en délaissant au programme le soin de préciser les caractéristiques à considérer en premier lieu.
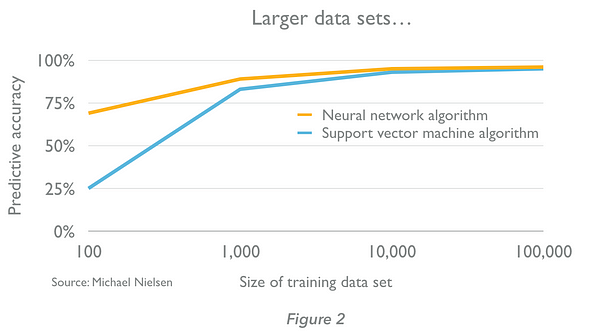
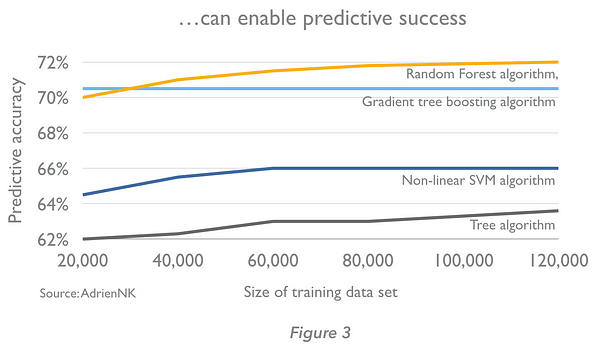
Les algorithmes du machine learning apprennent par l’entrainement. Un algorithme reçoit d’abord des exemples dont les résultats sont connus, note la différence entre ses prévisions et les résultats corrects, et s’accorde avec des pondérations pour affiner sa précision de ses prédictions jusqu’à ce qu’elles soient optimisés. La caractéristique des algorithmes en machine learning, est que la qualité de leurs prédictions s’améliore avec l’expérience. Plus nous leurs fournissons de données (jusqu’à un certain point), meilleurs sont les moteurs de prédiction (figures 2 et 3 – Notez que la taille des ensembles de données nécessaires sont très dépendants du contexte – nous ne pouvons pas généraliser à partir des exemples ci-dessous.)
Autres méthodes d’apprentissages.
Qui plus est, il y a plus de 15 méthodes d’apprentissage en ML, dont chacune utilise une structure algorithmique différente pour optimiser des prédictions basées sur les données reçues. Une approche deep learning (DL) - donne des résultats révolutionnaires dans de nouveaux domaines. Mais il y a beaucoup d’autres qui, bien qu’ils reçoivent moins d’attention, sont précieux en raison de leur large éventail d’utilisation. Certains des algorithmes ML les plus efficaces vont au-delà du deep learning, tels que :
- « random forest » qui créent une multitude d’arbres de décision pour optimiser une prédiction;
- « les réseaux bayésiens » qui utilisent une approche probabiliste pour analyser les variables et les relations entre elles; et
- « les machines à vecteurs » qui sont nourris d’exemples classés et créer des modèles pour affecter de nouvelles informations à l’une des catégories.
D’une part, chaque approche a ses avantages et inconvénients et les combinaisons peuvent être utilisés (un « ensemble » d’approche). Les algorithmes sélectionnés pour résoudre un problème particulier dépendra des facteurs, y compris la nature de l’ensemble des données disponibles. Dans la pratique, les développeurs ont tendance à expérimenter pour voir ce qui fonctionne le mieux.
D’autre part, les cas d’utilisation de ML varient en fonction de nos besoins et de l’imagination. Avec les bonnes données, nous pouvons construire des algorithmes à des fins innombrables, y compris les produits suggérant qu’une personne aime en fonction de leurs achats antérieurs; anticiper quand un robot dysfonctionnera sur une ligne d’assemblage de voitures ; estimer si une transaction par carte de crédit est frauduleuse, etc.
Deep learning : spécification des fonctionnalités.
Même avec une ML – random forest, réseaux bayésiens, machines à vecteurs – il est très difficile d’écrire des programmes qui fonctionnent bien. En effet, certaines tâches comme la compréhension de la parole, reconnaître des objets dans les images sont extrêmement complexes. Pourquoi ? Parce que nous ne pouvons pas préciser les caractéristiques d’une manière pratique et fiable. Si nous voulons écrire un programme informatique qui identifie les images de voitures par exemple, nous ne pouvons pas préciser les caractéristiques d’une voiture pour un algorithme. Il faudrait un algorithme avec un processus qui permettrait une identification correcte en toutes circonstances.
D’une part, les voitures viennent dans une large gamme de formes, de tailles et de couleurs. Leur position, l’orientation et la pose peuvent différer. L’arrière-plan, l’éclairage et une myriade d’autres facteurs influent sur l’apparence de l’objet. Même il y a trop de variations pour écrire un ensemble de règles. D’autre part, si l’on pouvait, ce ne serait pas une solution évolutive. Nous aurions besoin d’écrire un programme pour chaque type d’objet que nous voulions identifier.
Le deep learning est un sous-ensemble du machine learning – et l’une des 15 approches différentes. Tout Deep Learning est Machine Learning, mais pas tout Machine Learning est Deep Learning (figure 4).

Le Deep Learning est utile car il évite au programmeur d’avoir à assumer les tâches de spécification de fonction (définissant les caractéristiques à analyser à partir des données) et l’optimisation (comment peser les données pour fournir une prévision précise) – l’algorithme fait les deux.
Comment y parvenir ? La percée dans les ML est de modéliser le cerveau, pas le monde. Nos propres cerveaux apprennent à faire des choses difficiles. Prenons le cas de la compréhension de la parole et de la reconnaissance d’objets. En outre, le cerveau ne traite pas les info avec des règles exhaustives, mais par la pratique et la rétroaction. Comme un enfant qui apprend le monde autour de lui. Par exemple, voir une image d’une voiture, faire des prédictions (la voiture !) et recevoir des commentaires («oui!»). Par conséquent l’enfant a appris sans avoir un ensemble exhaustif de règles, l’enfant a appris par l’entrainement.
Évidemment, le Deep Learning utilise la même approche. Des petites calculatrices artificielles basées sur des logiciels, sont reliées entres elles. Elles ont un fonctionnement pratiquement similaire à la fonction des neurones de notre cerveau. C’est pourquoi, ils forment un « réseau neuronal » qui reçoit une entrée (pour continuer notre exemple, une image d’une voiture); les analyse; prend une décision à ce sujet et est informé si sa détermination est correcte. Dans l’hypothèse où la réponse est fausse, les connexions entre les neurones sont ajustées par l’algorithme. Et par conséquent va changer ses prévisions futures. Initialement, le réseau sera erroné plusieurs fois. Mais comme nous alimentons en millions d’exemples, les connexions entre les neurones seront réglées de sorte que le réseau neuronal rend des décisions correctes sur presque toutes les occasions. C’est en forgeant que nous devenons forgeron.
Grâce à ce processus, avec une efficacité croissante nous pouvons maintenant :
- reconnaître les éléments en images;
- traduire entre les langues en temps réel
- utiliser la parole pour commander des appareils (Google Apple et maintenant, Amazon Alexa et Microsoft Cortana);
- prédire comment la variation génétique effectuera la transcription d’ADN;
- analyser le sentiment dans les évaluations des clients;
- analyser les mauvais comportements en voiture ;
- détecter des tumeurs dans des images médicales ; et plus encore.
Cependant, le DL n’est pas bien adapté à tous les problèmes. En effet, il exige généralement de grands ensembles de données pour la formation. Ainsi, il faut une vaste puissance de traitement pour former et exploiter un réseau de neurones. Et puis il a un problème de « explicabilité » – il peut être difficile, voire impossible dans certains cas, de savoir comment un réseau neuronal développe ses prédictions ! Comme le cas de deux robots de Google qui cryptaient leur conversation et un troisième robot essayait de décrypter. Enfin, en libérant les programmeurs de la spécification de fonction complexe, le DL a livré des moteurs de prédiction à succès pour une série de problèmes importants. En conséquence, il est devenu un outil puissant dans la boîte à outils du développeur IA.